Mit Listen und Arrays arbeiten
Spyder
Bis jetzt hast du (I)Python direkt in der Shell gestartet und dein Skripte in einem beliebigen Editor geschrieben. Das ist die einfachste und flexibelste Möglichkeit mit Python zu arbeiten. Oft ist es aber praktischer mit einer IDE (Integrated Development Environment) zu arbeiten. Ich empfehle dir Spyder3.
Das abgebildete Fenster von Spyder hat drei Bereiche. Links ist ein Editor, in dem du deine Skripte schreiben kannst. Rechts unten, läuft eine interaktive Python-Session (normalerweise IPython mit Pylab). Rechts oben, sollte dir jeweils die Hilfe zum aktuellen Befehl angezeigt werden.
Du hast unterdessen sicher genügen Erfahrung um dich ohne weitere Anleitung mit
Spyder vertraut zu machen.
Tippe ein paar Befehle in die interaktive Session, öffne eines deiner Skripte und
lass es laufen oder erstelle ein neues kleines Skript.
Du hast diverse Möglichkeiten um die Oberfläche deinen Wünschen anpassen.
Praktisch ist zum Beispiel die Run-Toolbar unter
View > Windows and Toolbars > Run toolbar
Ausserdem kannst du unter "Tools > Prefences" viele weitere Dinge einstellen.
Insbesondere solltest du unter "Run" den Interpreter auf "Execute in a new dedicated
Python interpreter" umstellen.
Ich empfehle dir für den Rest dieses Tutorials Spyder zu verwenden. Du machst dir das Leben damit einiges einfacher.
Listen und Arrays
Bei unserem Beispiel zum Fallexperiment hast du gelernt was eine Liste ist und dass pylab zusätzlich noch Arrays kennt. Nun wird es Zeit, dass wir uns eingehender mit Listen und Arrays beschäftigen.
Was wissen wir bereits? Du weisst, dass du Listen mit [inhalt]
und Arrays mit array([inhalt]) erstellen kannst.
Du kannst Listen und Arrays mit den Befehlen range,arange,
frange,linspace erzeugen lassen.
Schliesslich weisst du, dass Rechnungen in denen Arrays vorkommen, auf jeden
Eintrag einzeln ausgeführt werden.
a = array([1,2,3]) sqrt(a) a**2 a*5
Mit Listen funktioniert das manchmal auch. Meist bekommst du aber eine Fehlermeldung oder ein unerwartetes Resultat.
l = [1,2,3] sqrt(l) l**2 l*5
Mehrere Dimensionen
Eine Liste ist ein sehr flexibler Datentyp. Du kannst alles mögliche zu einer Liste hinzufügen. Insbesondere können die Elemente einer Liste wieder Listen sein. So kannst du "mehrdimensionale" Listen erstellen.
l = [[1,2],[3,4,5]]
Auch Arrays können mehrere Dimensionen haben. Allerdings sollten die Einträge dann gleich lang sein.
a = array([[1,2],[3,4,5]]) a**2 # schlägt fehl a = array([[0,1,2],[3,4,5]]) a**2
Wenn beide Zeilen von a gleich lang sind, ist a nicht einfach eine Liste von Listen sondern ein wirkliches zweidimensionales Zahlenfeld. Das wird im nächsten Abschnitt wichtig.
Zugriff auf einzelne Elemente
Definiere die folgenden beiden Variablen
b = [1,2,3,4] c = array([9,8,7,6,5])
Manchmal wirst du auf ein einzelnes Element einer Liste oder
eines Arrays zugreifen wollen.
Du brauchst dafür die Notation b[3].
Die Zahl in den eckigen Klammern gibt den Index des gewünschten Elements. Achtung, die Nummerierung der Elemente beginnt mit 0!
Sind die Elemente wie bei l wieder Listen, so kannst du mehrere
eckige Klammern verwenden um auf ein Element zuzugreifen
l[0][0].
Das selbe gilt auch für Arrays: a[1][2].
Alternativ kannst du für Arrays auch nur eine eckige Klammer verwenden
und die Indizes mit Kommas abtrennen a[1,2].
In diesem Fall bezeichnet der erste Wert die gewünschte Zeile, der zweite die gewünschte Spalte.
Um herauszufinden wie viele Einträge deine Liste oder dein Array hat,
verwendest du len(c).
Wie lange sind b, l und a?.
Wieso bekommst du bei l und a nicht 5 bzw. 6?
Zugriff auf Bereiche
Manchmal wirst du auf Bereiche einer Liste zugreifen wollen.
Dafür kannst du : verwenden.
Alleine steht : für alle Elemente.
Setzt du vor oder nach : eine Zahl, so sind das die Grenzen.
Wie bei range() ist nur die Untergrenze enthalten.
b[1:] # Output: [2,3,4]
Um bei einem Array eine Auswahl zu treffen, solltest du die Komma-Notation verwenden.
Mit a[:,0:2] bekommst du die 0. und 1. Spalte von a.
(Was bekommst du bei a[:][0:2]? Verstehst du was passiert?
Wie ist das bei Listen?)
Schliesslich kannst du bei einem Array auch eine Liste mit Indizes übergeben. Damit lassen sich gezielt Elemente auswählen. Folgender Befehl wählt die Elemente a[0,2] (die Zahl 2) und a[1,1] (die Zahl 4) aus.
a[[0,1],[2,1]]
Aufgabe 1
Kopiere folgendes Array in dein Eingabefenster.
M = array([[1,1,2,3], [1,2,2,3], [0,0,3,3], [4,4,4,4]])
Verwende nun die Zugriffstechnik oben um auf die Einträge zuzugreifen und sie neu zu setzen. Am Schluss solltest du folgende Matrix erhalten.
1 1 2 3 1 1 2 3 4 4 3 3
M = array([[1,1,2,3], [1,2,2,3], [0,0,3,3], [4,4,4,4]]) M = M[:3,:] M[1,1] = 1 M[2,0:2] = 4
Objekte und Methoden
Eine weiteres, relativ häufiges Problem ist es, weitere Elemente zu
einer bestehenden Liste hinzuzufügen.
(Das funktioniert nur bei Listen, nicht bei Arrays.)
Dafür verwendest du die Methode append deines Listenobjekts.
liste = list(range(3,7)) liste.append(8)
Der letzte Satz enthält verschiedene neue Begriffe. Ein Objekt ist ein wichtiges Software-Konzept, das Objekten der realen Welt nachempfunden ist. Wie ein reales Objekt hat auch ein Software-Objekt Eigenschaften, gespeichert in Variablen, und Fähigkeiten, gegeben durch Methoden. Eine Methode ist eine Funktion, die zu einem Objekt gehört und etwas mit dem Objekt macht.
Unser Listenobjekt hat als besondere Variable seinen "Inhalt".
Daneben hat es verschiedene Methoden, wie eben append.
Die append-Methode nimmt ein weiteres Element und fügt es zum Inhalt der Liste hinzu.
Du kannst dir die Methoden eines Objekts anzeigen lassen, wenn du in einer interaktiven
IPython-Session objekt. eintippst und dann [tab] drückst.
Dabei ist objekt eine Variable, die das gewünschte Objekt enthält.
Auch Arrays sind Objekte wie du leicht kontrollieren kannst.
Arrays haben viele Methoden.
Die wichtigsten davon werden wir im Verlaufe dieses Tutorials noch kennenlernen.
Daneben hat ein Array noch weitere Variablen.
Diese Variablen enthalten zum Beispiel die Informationen, die du von len() nicht erhältst.
a.size a.ndim a.shape
Du siehst, um auf die Variablen eines Objekts zuzugreifen, verwendest du die gleiche Notation wie bei Funktionen, lässt aber die Klammern weg. Variablen können keine Argumente übernehmen.
Aufgabe 2
Schreibe ein Skript, das den Effekt der verschiedenen Methoden von Listenobjekten (nicht Arrays) zeigt.
# Mögliche Lösung liste = list(range(3,7)) # [3,4,5,6] liste.append(8) # [3,4,5,6,8] liste.insert(4,7) # [3,4,5,6,7,8] liste.extend([2,4,6]) # [3,4,5,6,7,8,2,4,6] print(liste.count(6)) # 2; 2 mal ist '6' in liste liste.remove(6) # [3,4,5,7,8,2,4,6] print(liste.count(6)) # 1; 1 mal ist '6' in liste print(liste.index(4)) # 1; erste '4' ist bei Index 1 liste.sort() # [2,3,4,4,5,6,7,8] liste.reverse() # [8,7,6,5,4,4,3,2] print(liste.pop()) # 2; [8,7,6,5,4,4,3]
Nützliche Tipps
where
Die Möglichkeit eines Arrays eine Liste von Indizes auszuwählen
wird dank where noch nützlicher.
a[where(a>3)] where(a>3)
In seiner einfachsten Form hat where als Argument eine Bedingung. Die Bedingung wird dabei für jedes Array-Element einzeln ausgewertet. Der Rückgabewert von where ist ein Array mit den Indizes all jener Elemente, welche die Bedingung erfüllt hatten. (Bzw. mehrere Arrays bei mehreren Dimensionen.)
Folgende Tabelle enthält die wichtigsten Vergleichsoperatoren, mit denen du deine Bedingung zusammenstellen kannst.
== | gleich (nur ein = ist eine Zuweisung!) |
!= | ungleich |
< | kleiner als |
<= | kleiner gleich |
>= | grösser gleich |
> | grösser als |
Runden
Wenn du mit Floats (reellen Zahlen) arbeitest, wirst du immer Mal wieder runden müssen.
Dank pylab stehen dafür verschiedene Funktionen zur Verfügung.
Löse die nächste Aufgabe mit den folgenden Befehlen:
sign, around, a.round (Methode eines Arrays), floor,
ceil, fix.
Aufgabe 3
Definiere folgende Variable:
f = array([-1.45, 2.45, 3.55]).
- Rund f in Richtung 0.
- Rund f ab.
- Rund f auf.
- Rund f auf 1 Nachkommastelle.
- Bestimme die Vorzeichen von f.
f = array([-1.45, 2.45, 3.55]) fix(f) floor(f) ceil(f) around(f, 1) f.round(1) sign(f)
Hinweis: Wie die Aufgabe zeigt, runden die pylab-Befehle
around(f) und f.round() 5 zur nächsten geraden Zahl.
Durch dieses Verfahren wird gleich häufig auf- wie abgerundet.
Der standard round()-Befehl von Python rundet 5 immer auf.
Er akzeptiert aber nur Zahlen und keine Listen oder Arrays.
Ein komplexeres Beispiel
In unserem Beispiel zum Fall-Experiment, hatten wir für jede Höhe bloss eine einzelne Messung gemacht. Nun wollen wir annehmen, dass mehrere Messungen gemacht worden sind. Die Resultate der Messungen sind in der Datei fall.txt gespeichert. Speichere diese Datei in dein Arbeitsverzeichnis.
Dateien einlesen
Oft wirst du mit Daten arbeiten wollen, die du in irgend einer Art
bereits auf dem Computer gespeichert hast.
In diese Fällen möchtest du sie natürlich nicht neu eintippen
und auch Copy-Paste ist keine elegante Lösung.
Die einfachste Möglichkeit solche Daten zu importieren, ist der
Befehl loadtxt('filename').
Damit kannst du Zahlen aus einer Textdatei einlesen.
# einlesen fall = loadtxt('fall.txt') # zugreifen (in einer interaktiven Session) fall
Wenn du dir fall.txt in einem Editor anschaust, siehst du,
dass die einzelnen Messungen durch Leerzeichen getrennt sind.
Das ist das Standardformat für loadtxt.
Wenn deine Datei eine andere Struktur hätte, so müsstest du die nötigen
Informationen als weitere Argumente übergeben.
Meist wirst du die Keyword-Argumente comments und
delimiter benötigen.
Statistik Befehle
fall enthält nun alle Zahlen aus unserer Input-Datei.
Um diese Zahlen auszuwerten brauchen wir Statistik-Befehle.
Die folgende Tabelle fasst die wichtigsten Befehle zusammen.
min(l) | Kleinstes Element in l (nur für Listen). |
max(l) | Grösstes Element in l (nur für Listen). |
amin(a) | Kleinstes Element in a. |
amax(a) | Grösstes Element in a. |
mean(a) | Mittelwert der Elemente in a. |
std(a) | Standardabweichung der Element in a. |
a.min(d) | Kleinstes Element in a entlang d. |
a.max(d) | Grösstes Element in a entlang d. |
a.mean(d) | Mittelwert des Arrays a entlang der Dimension d. |
a.std(d) | Standardabweichung der Element in a entlang d. |
Die ersten beiden Befehle funktionieren nur für Listen. Die nächsten vier verstehen sowohl Listen als auch Arrays. Sie akzeptiert eine Dimension (0: Spalten, 1: Zeilen) als zweiten Parameter und berechnen oder suchen ihren Wert dann entlang dieser Dimension.
a = array([[1,2,1,2,1,2], [3,4,3,4,3,4]]) mean(a, 1) # array([ 1.5, 3.5]) mean(a, 0) # array([ 2., 3., 2., 3., 2., 3.])
Für Arrays ist die Notation der letzten vier Zeilen aber besser lesbar. Ein Beispiel: Mit folgendem Befehel kannst du die Mittelwerte für die verschiedenen Höhen berechnen lassen.
t_mean = fall[:,1:].mean(1)
Aufgabe 4
Erstelle eine neue Grafik zum Fall-Experiment. Verwende dieses Mal die Werte aus fall.txt.
- Speichere die Höhen aus fall in ein Array h.
- Erstelle ein Array mit dem Mittelwert für jede Höhe.
- Erstelle ein Array mit der Standardabweichung für jede Höhe.
- Plotte die Mittelwerte gegen die Höhe und verwende die Standardabweichungen/sqrt(10) für die Fehlerbalken.
- Zeichne eine Kurve für die Theorie.
from pylab import * fall = loadtxt('fall.txt') h = fall[:,0] t_mean = fall[:,1:].mean(1) t_std = fall[:,1:].std(1) errorbar(t_mean, h, xerr=t_std/sqrt(10), fmt='x') h_theorie = frange(0,10,0.01) t_theorie = sqrt(2/9.81*h_theorie) plot(t_theorie,h_theorie) show()
Grafik-Objekte
Die Lösung zur letzten Aufgabe verwendet die globalen Grafik-Befehle
des Pyplot Modules.
Nachdem wir nun Objekte eingeführt haben, könnten wir aber auch hier
die Objekt-Syntax verwenden.
Auch ein Grafikfenster oder die Achsen mit der dazugehörigen
Zeichenfläche sind Objekte.
Die meisten Grafik-Befehle sind Methoden des Achsenobjekts.
In der Lösung oben ruft Pylab jeweils einfach die
entsprechende Methode des neusten Achsenobjekts auf.
Wollen wir die Objekt-Syntax verwenden, erstellen wir zuerst
mit ax = axes() ein neues Achsenobjekt ax.
Anschliessend verwenden wir dessen Methoden um die Punkte,
Linien und Fehlerbalken zu zeichnen.
from pylab import * fall = loadtxt('fall.txt') h = fall[:,0] t_mean = fall[:,1:].mean(1) t_std = fall[:,1:].std(1) ax = axes() ax.errorbar(t_mean, h, xerr=t_std/sqrt(10), fmt='x') h_theorie = frange(0,10,0.01) t_theorie = sqrt(2/9.81*h_theorie) ax.plot(t_theorie,h_theorie) show()
Diese Notation ist flexibler und expliziter, als die Verwendung der globalen Befehle. (Du kannst Nachträglich in ein altes Achsenobjekt zeichnen und weisst immer welche Achsen von einem Befehl betroffen sind.) Die Globale-Syntax hingegen ist kürzer und deshalb oft übersichtlicher. Da wir keine komplexen Programme schreiben, verwenden wir deshalb in diesem Tutorial die globalen Befehle.
Histogramme
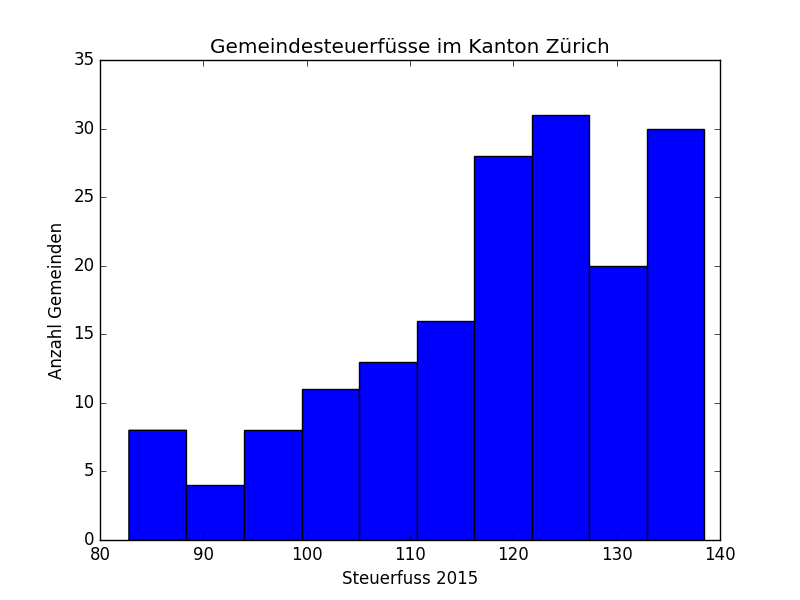
Was ist ein Histogramm? Ein Histogramm ist eine graphische Darstellung der Häufigkeitsverteilung von Werten. Im Beispiel oben die Verteilung der Steuerfüsse im Kanton Zürich. Histogramme sind ein wichtiges Mittel in der Datenanalyse. Angenommen dein Input besteht aus Kugeln, die mit den Werten beschriftet sind. Du kannst dir ein Histogram wie eine Reihe aus Rohren (Bins) vorstellen. Jedes Rohr entspricht einem Wertebereich (0.5-1.5, 1.5-2.5,...). Jede Kugel im Input wird nun in das passende Rohr einsortiert. Die resultierenden Füllstände, sind dann das Histogram.
Falls du mit Histogrammen noch nicht vertraut bist, ist ein praktisches Beispiel wohl am nützlichsten. Speichere histogram.py in dein Arbeitsverzeichnis und starte das Programm in der Shell.
python3 histogram.py
Das Programm fragt dich nach einem Wert und füllt diesen dann in ein Histogram. Anschliessend kannst du den nächsten Wert eintippen. Dies wiederholt sich bis du einen Wert kleiner oder gleich 0 eintippst. Das Histogram hat 10 Bins zwischen 0.5 und 10.5. Fülle dein Histogram mit Integer- und Float-Werten oder mit Zahlen ausserhalb des Bin-Bereichs. Überlege dir jeweils wo der Wert hinkommt, bevor du [enter] drückst.
3, 4.2, 6, 3.9, 2.3, 4.9, 5.1, 11, 8.499, 8.5, 3.9
In Python erzeugst du Histogramme mit dem Befehl hist.
n, bins, patches = hist(l, nBins)- Füllt die Elemente der Liste oder des Arrays l in ein Histogram dessen Anzahl Bins gleich nBins ist.
(nBins muss ein Integer sein.) n, bins, patches = hist(l, binEdges)- Füllt die Elemente von l in ein Histogram mit Bin-Grenzen bei binEdges.
(binEdges ist eine Liste.)
Die Rückgabewerte sind dabei:
n- ein Array mit der Anzahl Einträge in den Bins
bins- ein Array mit den Bin-Grenzen
patches- eine Liste mit Grafikobjekten für das Rechteck jedes Bins.
Du kannst die Rückgabewerte auch einfach ignorieren, wenn du dein Histogram bloss Zeichnen möchtest.
Zusätzlich zu hist gibt es noch den Befehl bar(lower,height,width).
Damit kannst du ein Balkendiagramm zeichnen, wenn du die untere Grenze der Balken, ihre Höhe und ihre Breite kennst.
Beispielsweise Aufgrund von n und bins.
from pylab import * # Input a = [5,5,7,7,9,9,4,3,7,1,7,5,4,2,1,5,8,2] subplot(2,1,1) # Histogram mit Bins: 0.5-1.5, 1.5-2.5, ..., 8.5-9.5 n, bins, patches = hist(a, frange(0.5,9.5,1)) title("hist") print(n) print(bins) subplot(2,1,2) lower_edges = bins[:bins.size-1] bar(lower_edges, n, 1) title("bar") show()
hist kann noch viel mehr.
Du kannst zum Beispiel gleichzeitige mehrere Datensets zeichnen oder
die Fläche des Histogramms normieren.
Schaue dir für die folgende Aufgabe hist? an.
Aufgabe 5
Erstelle Histogramme für folgende beiden Datensets. Probiere dabei verschiedene Histogram-Optionen und -Einstellungen aus.
a = [15,36,6,37,21,24,1,18,4,24,0,22,22,27,32,24,27,16,17,4] b = [[-0.02,0.14,-0.12,0.74,-1.03,-1.2,0.94,-0.1,0.41,-1.18], [1.29,-0.09,-0.19,1.33,-0.05,0.58,-1.87,0.29,-1.14,0.24]]
Hinweis: Wenn t ein n-dimensionales Array ist, kannst du diese mit t.flatten()
1-dimensional zurückgeben lassen.
from pylab import * a = [15,36,6,37,21,24,1,18,4,24,0,22,22,27,32,24,27,16,17,4] b = [[-0.02,0.14,-0.12,0.74,-1.03,-1.2,0.94,-0.1,0.41,-1.18], [1.29,-0.09,-0.19,1.33,-0.05,0.58,-1.87,0.29,-1.14,0.24]] row = 2 col = 2 i = 1 subplot(row,col,i) i = i+1 hist(a, 5, color='g') title("A") subplot(row,col,i) i = i+1 hist(b, 5, orientation="horizontal") title("B") subplot(row,col,i) i = i+1 hist(b, 5, histtype='barstacked', color=['b','r']) title("B Stacked") subplot(row,col,i) i = i+1 hist(array(b).flatten(), 5, normed=True) title("B Flat") show()
Ein Histogram-Beispiel
Die Zeitmessungen im Fallexperiment wurden wahrscheinlich alle mit der gleichen Methode gemacht. Sie sollten also alle mit der gleichen Unsicherheiten behaftet sein. Statt die Standardabweichung für jede Höhe einzeln zu berechnen, könnten wir sie auch für alle 100 Werte gemeinsam bestimmen. Zuerst wollen wir aber überprüfen ob die Messabweichungen aus einer einzigen Verteilung stammen könnten. Dazu erstellen wir ein Histogram mit den Abweichungen zwischen Messwert und dazugehörigem Mittelwert. Als Erstes brauchen wir die Mittelwerte sowie ein Array, das die Zeiten enthält.
from pylab import * fall = loadtxt('fall.txt') t = fall[:,1:] t_mean = t.mean(1)
Nun wollen wir abweichungen = t - t_mean berechnen.
Der Befehl oben funktioniert aber leider nicht.
Python führt die Subtraktion zeilenweise aus, subtrahiert also
von jedem Messwert einer Zeile einen anderen Mittelwert.
Um das richtige Resultat zu erhalten musst du entweder t
transponieren oder t_mean in einen Spalten-Vektor verwandeln.
abweichungen = t.T - t_mean # transponiert abweichungen = t - t_mean.reshape(-1,1) # Spalte
Schliesslich kannst du die Werte nun in ein Histogram zeichnen. Dabei müssen alle Werte als ein grosses Dataset betrachtet werden.
hist(abweichungen.flatten(),10)
Das resultierende Histogram entspricht ziemlich gut einer Normalverteilung. Die Abweichungen stammen also tatsächlich alle von einer einzigen Verteilung. Berechne nun die Standardabweichung über alle Differenzen und verwende diese in deiner Grafik zum Fall-Experiment für die Berechnung der Fehlerbalken.
Aufgaben zur Vertiefung
Zählen
Wie viele Einträge des folgenden Arrays sind grösser als 0.5
array([ 0.9 , 0.87, 0.09, 0.04, 0.8 , 0.73, 0.49, 0.7 , 0.39, 0.05, 0.84, 0.42, 0.3 , 0.31, 0.88, 0.75, 0.97, 0.61, 0.75, 0.21, 0.13, 0.23, 0.39, 0.49, 0.03, 0.29, 0.88, 0.13, 0.44, 0.92, 0.05, 0.53, 0.8 , 0.61, 0.19, 0.02, 0.35, 0.97, 0.07, 0.5 , 0.43, 0.39, 0.06, 0.49, 0.37, 0.09])
(Von Hand zählen ist NICHT die richtige Lösung)
Objekt-Notation
Passe eine oder mehrere deiner Lösungen mit Grafiken so an, dass sie die Objekt-Schreibweise verwendet. Leider sind die Methoden-Namen nicht immer identisch mit den Namen der globalen Befehle. Um den Namen einer Methode zu finden, nutzt du am besten die Tab-Completion von IPython oder das Cheatsheet.
Zürichsee
Speichere die Datei zuerichsee.csv in dein Arbeitsverzeichnis.
Lade sie anschliessend mit loadtxt (und den richtigen Argumenten) in deine Python Session.
zuerichsee.csv enthält den Wasserstand des Zürichsees für jeden Tag des Jahres 2008. (Quelle: Hydrologisches Jahrbuch der Schweiz 2008) Beantworte mit Hilfe der Statistik-Befehle folgenden Fragen für ausgewählte Monate und für das ganze Jahr:
- Was ist der mittlere Wasserstand
- Was ist die Standardabweichung dieses Wertes
- Was ist der Unterschied zwischen minimalem und maximalem Wasserstand.
Stelle ausserdem den Verlauf des Pegelstands für ausgewählte Monate in einer Grafik dar.
Erstelle schliesslich ein Histogram der Werte des gesamten 2008. Wähle Bereich und Anzahl Bins so, dass du eine informative Verteilung erhältst
